EKS 클러스터에 새 서비스를 배포했다. Pod도 떴고, 내부 health check도 통과한다. 마지막으로 api 응답을 확인하고 테스트를 마무리하려고 하는데, 응답값이 504 Gateway Time-out이 반환된다.
원인은 의도치 않게 들어간 Terraform 설정 한 줄이었다. 하지만 그 한 줄이 문제인지를 알기까지 꽤 오랜 시간이 걸렸다. 이를 알기 위해서는, 먼저 “ALB의 트래픽이 Pod까지 어떻게 도달하는가”를 이해해야 했다.
이 글은 EKS환경에서 pod까지 어떻게 네트워크 트래픽이 들어가는지 하나씩 짚어가면서 추적한 과정을 기록한 것이다.
먼저 알아야 할 것
이 글을 이해하기 위해 먼저 중요한 몇 가지 개념들을 쉽게 알아보도록 하자.
1. ALB는 Pod에 어떻게 트래픽을 보낼까?
EKS에서 ALB(Application Load Balancer)가 Pod에 트래픽을 전달하는 방식은 ip, instance 타입 두 가지가 있다. 각각의 차이를 그림으로 나타내면 다음과 같다.
graph LR subgraph "target-type: instance" Client1[클라이언트] --> ALB1[ALB] ALB1 --> Node1["노드 IP:NodePort"] Node1 --> Pod1[Pod] end subgraph "target-type: ip" Client2[클라이언트] --> ALB2[ALB] ALB2 --> Pod2["Pod IP:Port (직접)"] end
target-type: instance: ALB → 노드 IP의 NodePort → kube-proxy가 Pod로 전달. 한 단계를 더 거친다.
target-type: ip: ALB → Pod IP로 직접 전달. 노드를 경유하지 않아 더 효율적이다.
이 글에서 다루는 환경은 target-type: ip를 사용한다. 이 방식에서는 ALB가 Pod IP로 직접 패킷을 보내는데, 이 패킷이 Pod에 도달하려면 중간에 있는 방화벽(Security Group)이 이 트래픽을 허용해야 한다.
2. Security Group이란?
AWS에서 Security Group(SG)은 네트워크 인터페이스(ENI)에 붙는 가상 방화벽이다. 인바운드(들어오는) 룰과 아웃바운드(나가는) 룰로 구성된다.
graph LR Traffic["외부 트래픽<br/>(ALB)"] -->|"port 7001"| SG{"Security Group<br/>인바운드 룰 확인"} SG -->|"허용"| ENI["노드 ENI"] --> Pod SG -.->|"룰 없음 → 차단"| Drop["패킷 드롭"]
중요한 점은, 인바운드 룰에 명시적으로 허용되지 않은 트래픽은 기본적으로 모두 차단된다는 것이다. ALB에서 Pod의 7001 포트로 트래픽을 보내려면, Pod가 있는 노드의 SG에 “ALB에서 오는 7001 포트 트래픽을 허용한다”는 명시적인 인바운드 룰이 반드시 있어야 한다.
그렇다면 이 인바운드 룰은 누가 만들어주는 걸까? 내가 만들어야 하나?
3. AWS Load Balancer Controller의 SG 자동 관리
여기서 AWS Load Balancer Controller(이하 LBC)가 등장한다. LBC는 EKS에서 Ingress 리소스를 보고 ALB를 생성해주는 컨트롤러인데, ALB 생성 외에 한 가지 중요한 역할을 더 한다: SG 인바운드 룰을 자동으로 관리해준다.
서비스가 배포될 때마다 운영자가 수동으로 SG 룰을 열어줄 필요가 없도록 설계된 것이다.
sequenceDiagram participant Operator as 운영자 participant LBC as LB Controller participant ALB as ALB participant SG as 노드 Security Group participant Pod as Pod Operator->>LBC: Ingress 리소스 생성 LBC->>ALB: ALB + Target Group 생성 LBC->>LBC: Pod가 있는 노드의 SG를 찾는다 LBC->>SG: 인바운드 룰 자동 추가<br/>"ALB → Pod 포트 허용" Note over SG: 이제 ALB 트래픽이 통과 가능 ALB->>Pod: Health check 요청 Pod-->>ALB: 200 OK Note over ALB: Target: healthy
정상적인 흐름이라면, LBC가 알아서 SG 룰을 추가하고, ALB health check가 통과하고, 트래픽이 흐른다.
504 Gateway Time-out
내가 504 응답을 받은 과정을 풀어보면 다음과 같다.
아래 로그는 새 서비스를 배포한 직후의 상태다. Pod 2개가 정상적으로 Running이다.
$ kubectl get pods -n myapp -o wide
NAME READY STATUS RESTARTS AGE
myapp-api-6bff8d9657-6qf6k 1/1 Running 0 7m
myapp-api-6bff8d9657-kwh52 1/1 Running 0 6m
Pod 내부에서 health check 엔드포인트를 호출하면 정상 응답한다.
$ kubectl exec myapp-api-6bff8d9657-6qf6k -- \
node -e "require('http').get('http://localhost:7001/readyz', r => {
let d=''; r.on('data',c=>d+=c); r.on('end',()=>console.log(r.statusCode,d))
})"
200 {"status":"ready"}
하지만 ALB 도메인으로 같은 요청을 보내면 504가 온다.
$ curl -sk https://k8s-myapp-xxxxxxxx.ap-northeast-2.elb.amazonaws.com/readyz
<html>
<head><title>504 Gateway Time-out</title></head>
</html>
Pod 안에서는 되는데, 밖에서는 안 된다. 어딘가에서 막히고 있다. 그리고 보통 타임아웃은 (아주 높은 확률로) Security Group이 막힐 때 발생한다.
가설과 검증
1단계: ALB에서 Pod가 보이는가?
ALB는 등록된 타겟에 주기적으로 health check 요청을 보낸다. 모든 타겟이 unhealthy이면 요청을 전달할 곳이 없으므로 504를 반환한다. 먼저 Target Group의 health 상태를 확인했다.
$ aws elbv2 describe-target-health --target-group-arn <tg-arn>
Target: 10.0.1.78:7001 → unhealthy (Target.Timeout)
Target: 10.0.2.175:7001 → unhealthy (Target.Timeout)
두 타겟 모두 Target.Timeout이다. ALB가 Pod IP의 7001 포트로 health check 요청을 보냈지만, 정해진 시간 내에 응답을 전혀 받지 못했다는 뜻이다.
여기까지 내용을 짚어보자. Security Group이 높은 확률로 문제라는 것을 추론할 수 있다.
graph LR subgraph "확인된 사실" A["Pod 내부: /readyz → 200 OK"] -->|"애플리케이션은 정상"| C B["ALB → Pod IP:7001 → Timeout"] -->|"네트워크에서 차단"| C C{"원인은 어디?"} end C -->|"target-type: ip이므로<br/>ALB가 Pod IP로 직접 전송"| D["Security Group을<br/>확인해야 한다"]
- Pod 내부에서는
/readyz가 200을 반환한다 → 애플리케이션 문제는 아니다 - ALB에서 Pod IP로 요청하면 timeout → 응답이 안 온 게 아니라 요청 자체가 도달하지 못하고 있다
target-type: ip에서 이런 증상이면 → SG에서 트래픽이 차단되고 있을 가능성이 가장 높다
2단계: SG 인바운드 룰이 없다면, 왜 LBC가 추가하지 않았는가?
앞서 설명한 대로, LBC가 SG 인바운드 룰을 자동으로 관리해준다. 그런데 지금 ALB 트래픽이 Pod에 도달하지 못하고 있다면, LBC가 이 룰 추가에 실패했을 가능성이 있다고 생각할 수 있다.
LBC 로그를 확인했다.
$ kubectl logs -n kube-system \
-l app.kubernetes.io/name=aws-load-balancer-controller --tail=3
{"level":"error",
"msg":"Requesting network requeue due to error from ReconcileForPodEndpoints",
"error":"expected exactly one securityGroup tagged with
kubernetes.io/cluster/my-prod-eks for eni eni-0cd3e14xxxxxxxx,
got: [sg-00f20xxxxxxxxxx sg-01e1fxxxxxxxxxx]"}
이 에러가 15초 간격으로 반복되고 있었다. 에러 메시지를 풀어보면:
“Pod ENI에 연결된 SG 중,
kubernetes.io/cluster/my-prod-eks태그가 붙은 것이 정확히 1개여야 하는데, 2개가 발견되었다.”
왜 1개여야 할까? 2개는 안되나?
이걸 이해하려면 LBC가 하는 일을 먼저 알아야 한다. 개념이 어려울 수 있어서, SG를 건물 출입 명부에 비유해서 설명해보자.
ALB가 Pod에 접근하려면, Pod 쪽 명부(Security Group)에 “ALB는 입장 가능”이라는 항목이 있어야 한다. 이 항목을 LBC가 자동으로 써준다. 문제는 Pod ENI에 명부가 여러 개 붙어 있을 수 있다는 것이다. 여러 명부 중 어디에 써야 할까?
LBC의 기준은 이렇다. EKS는 클러스터를 생성할 때 노드 SG에 kubernetes.io/cluster/{클러스터명} 태그를 자동으로 붙인다. (AWS 공식 문서) LBC는 이 태그가 붙은 명부를 찾아서, 거기에만 룰을 추가한다.

그리고 LBC는 이 태그가 달린 명부가 정확히 1개일 것을 기대한다. “2개면 둘 다 적으면 되지 않나?”라고 생각할 수 있는데, LBC 소스 코드의 주석은 이렇게 설명한다:
If there are multiple securityGroup attached, we expect one and only one securityGroup is tagged with the cluster tag. (
networking_manager.go)
즉 “어느 명부에 룰을 추가할지 명확히 결정하기 위해서” 정확히 1개를 요구하는 것이다. 2개 이상이면 어떤 명부가 대상인지 특정할 수 없으므로 룰 추가를 중단하고 에러를 낸다.
그렇다면 명부에 뭐라고 적을까? ALB의 IP를 적는 것이 가장 직관적이다. 그런데 ALB IP는 언제든 바뀔 수 있다. LBC 문서에서는 이렇게 경고한다:
Avoid using the IP addresses of a specific AWS Load Balancer, these IPs are dynamic and the security group rules aren’t updated automatically. (LBC Security Group 문서)
ALB가 스케일링되거나 교체되면 IP가 바뀌는데, SG 룰은 자동으로 갱신되지 않아 트래픽이 차단된다. 또한 ALB가 여러 개면 각각 IP가 달라서 명부에 줄이 그 수만큼 늘어난다.
그래서 LBC는 다른 방식을 쓴다. 클러스터당 사원증(Backend SG) 을 1개 만들어서 모든 ALB에 달아준다. 그러면 명부에 “이 사원증 소지자는 입장 가능”이라고 한 줄만 적으면, ALB가 10개로 늘어도 명부를 수정할 필요가 없다. LBC Security Group 문서에서는 이렇게 설명한다:
LBC uses a single, shared backend security group, attaching it to each load balancer and using as the traffic source in the security group rules it adds to targets.
정리하면 LBC는 두 종류의 SG를 다루는 것이다:
flowchart LR subgraph ALB B["Backend SG<br/><small>LBC가 자동 생성</small>"] end subgraph Pod ENI C["클러스터 태그 SG<br/><small>kubernetes.io/cluster/{name}</small>"] end B -->|"트래픽"| C LBC["LBC"] -.->|"① Backend SG를<br/>ALB에 붙임"| B LBC -.->|"② 클러스터 태그 SG에<br/>인바운드 룰 추가<br/><small>소스: Backend SG</small>"| C style B fill:#dbeafe style C fill:#d1fae5 style LBC fill:#fef3c7
- Backend SG (ALB 쪽): LBC가 클러스터당 1개 자동 생성한다(
k8s-traffic-{클러스터명}-{hash}). 클러스터 내 모든 ALB가 이 SG를 공유하므로, Pod 쪽에는 인바운드 룰 하나만 추가하면 어떤 ALB에서 오는 트래픽이든 허용된다. - 클러스터 태그 SG (Pod 쪽): EKS가 클러스터 생성 시 자동으로
kubernetes.io/cluster/{클러스터명}태그를 붙인다. “Backend SG 소지자는 입장 가능”이라는 인바운드 룰이 여기에 추가된다.
LBC가 하는 일은 “backend SG에서 오는 트래픽을 허용한다”는 룰을 클러스터 태그 SG에 추가하는 것이다. 이때 클러스터 태그가 붙은 SG가 2개 이상이면, 어디에 룰을 넣을지 결정할 수 없어 실패한다.
flowchart TD A["Pod ENI에 붙은 SG 목록 조회"] --> B["kubernetes.io/cluster 태그가<br/>있는 SG 필터링"] B --> C{"태그된 SG가<br/>몇 개인가?"} C -->|"1개"| D["그 SG에 인바운드 룰 추가<br/>ALB → Pod 포트 허용"] D --> E["ALB health check 통과"] C -->|"0개"| F["에러: 대상 SG를 찾을 수 없음"] C -->|"2개 이상"| G["에러: 어느 SG에 추가할지 결정 불가"] F --> H["인바운드 룰 미추가<br/>→ ALB 트래픽 차단 → 504"] G --> H style C fill:#fff3cd style G fill:#f8d7da style H fill:#f8d7da style D fill:#d4edda style E fill:#d4edda
지금 상황은 “2개 이상” 케이스다. LBC가 판단을 내리지 못하고 아무것도 하지 않았다. 그래서 인바운드 룰이 추가되지 않았고, ALB 트래픽이 SG에서 차단된 것이다.
3단계: 왜 태그된 SG가 2개인가?
이 질문에 답하려면, EKS 클러스터의 SG 구조를 이해해야 한다.
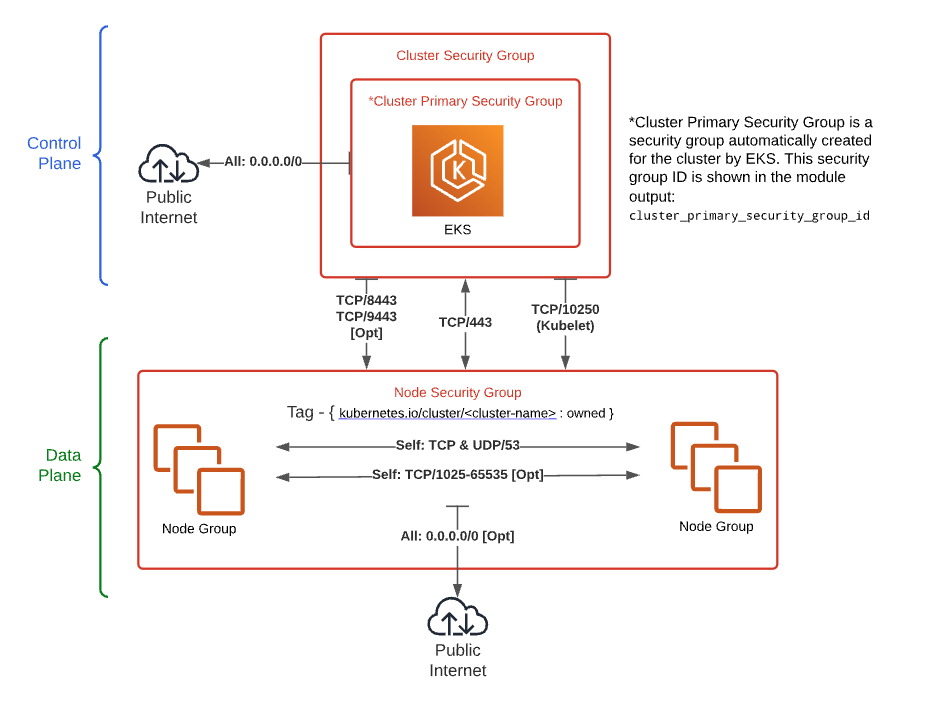
EKS 클러스터에는 두 종류의 SG가 존재한다:
graph TB subgraph "EKS 클러스터" subgraph "Control Plane (AWS 관리)" CP[Control Plane ENI] CSG["클러스터 Primary SG<br/><small>EKS가 자동 생성</small><br/><small>self-referencing 룰:<br/>같은 SG끼리 모든 트래픽 허용</small>"] CP --- CSG end subgraph "Data Plane (노드)" Node[노드 ENI] NSG["노드 SG<br/><small>Terraform이 생성</small><br/><small>개별 포트 룰:<br/>kubelet 10250, webhook 등</small>"] Node --- NSG end end CSG -.->|"보통은 연결 안 됨"| Node style CSG fill:#e3f2fd style NSG fill:#fff3e0
클러스터 Primary SG: EKS가 클러스터를 만들 때 eks-cluster-sg-<cluster-name>-<uniqueID> 이름으로 자동 생성한다. 기본 인바운드 룰은 “같은 SG끼리 모든 트래픽을 허용”하는 self-referencing 룰이고, 이 룰을 삭제해도 EKS가 클러스터 업데이트 시 재생성한다. EKS가 kubernetes.io/cluster/{name}: owned 태그를 자동으로 붙이며, 이 태그도 삭제하면 재생성된다. (AWS EKS Security Group 문서)
노드 SG: terraform-aws-eks 모듈이 노드그룹을 위해 별도로 생성한다. Control Plane에서 노드로 필요한 포트 — kubelet(10250), API(443), webhook(4443/6443/8443/9443/10251), CoreDNS(53), ephemeral ports(1025-65535) — 를 개별적으로 열어놓는다. node_security_group_enable_recommended_rules = true(기본값)일 때 이 룰들이 자동 생성된다. 이 모듈도 kubernetes.io/cluster/{name}: owned 태그를 붙인다. (terraform-aws-eks 소스)
보통은 노드에 노드 SG만 연결된다. 노드 SG에 필요한 포트 룰이 이미 다 들어있으므로, 클러스터 SG를 노드에 추가로 붙일 필요가 없다. terraform-aws-eks의 FAQ에서도 이 점을 명시하고 있다: 두 SG가 동시에 노드에 붙으면 둘 다 kubernetes.io/cluster 태그를 가지게 되어 LBC와 충돌한다. (terraform-aws-eks FAQ)
그런데 노드에 어떤 SG가 붙어있는지 직접 확인해보니:
$ aws ec2 describe-instances --instance-ids <node-id> \
--query "Reservations[0].Instances[0].SecurityGroups[*].[GroupId,GroupName]"
sg-01e1fxxxxxxxxxx eks-cluster-sg-my-prod-eks-XXXXXXXXX # 클러스터 SG
sg-00f20xxxxxxxxxx my-prod-eks-node # 노드 SG
노드에 SG가 2개 연결되어 있었다. 클러스터 SG가 노드에까지 붙어있는 것이다. 두 SG 모두 클러스터 태그가 있다:
sg-01e1f... → kubernetes.io/cluster/my-prod-eks: owned (EKS 자동 생성)
sg-00f20... → kubernetes.io/cluster/my-prod-eks: owned (Terraform 생성)
이것이 LBC 에러의 직접적인 원인이다. 왜 똑같은 이름의 SG가 두 개나 붙어있었을까?
The port range Backend Security Group Rules not generated #3737 깃헙 이슈를 찾아보니 나와 정확히 동일한 이슈를 겪은 사람이 있었다.
expected exactly one securityGroup tagged with kubernetes.io/cluster/<cluster-name> for eni <eni-id>, got: [sg-xxx sg-yyy]
관련 이슈들을 정리하면 아래와 같다.
- Expect exactly one securityGroup tagged with kubernetes.io/cluster/eks-1 for ENI · Issue #1897 · kubernetes-sigs/aws-load-balancer-controller
- Terraform Registry
참고로 테라폼 레지스트리에 아래와 같이
내 Terraform 코드를 확인해보니 위 이슈와 정확하게 똑같은 이슈였다!
# eks.tf
eks_managed_node_groups = {
app = {
...
attach_cluster_primary_security_group = true
}
}attach_cluster_primary_security_group = true. terraform-aws-eks 모듈의 이 옵션으로, 클러스터 Primary SG를 노드 ENI에 추가로 연결한다. 기본값은 false이다. (terraform-aws-eks variables.tf)
이 설정이 켜지면 노드 구조가 이렇게 바뀐다:
graph TB subgraph "attach = false (기본값)" Node1[노드 ENI] NSG1["노드 SG<br/>클러스터 태그 ✓"] Node1 --- NSG1 Note1["태그된 SG: 1개<br/>→ LBC 정상 동작"] style Note1 fill:#d4edda end subgraph "attach = true (문제)" Node2[노드 ENI] NSG2["노드 SG<br/>클러스터 태그 ✓"] CSG2["클러스터 SG<br/>클러스터 태그 ✓"] Node2 --- NSG2 Node2 --- CSG2 Note2["태그된 SG: 2개<br/>→ LBC 에러"] style Note2 fill:#f8d7da end
4단계: 정상 동작하는 클러스터와 비교
추측만으로 결론을 내리지 않기 위해, 같은 조직의 다른 프로덕션 클러스터와 비교했다. 해당 클러스터는 동일한 구성 — ALB + target-type: ip + terraform-aws-eks 모듈 — 에서 아무 문제 없이 동작하고 있다.
정상 클러스터 노드: SG가 1개만 연결되어 있다
$ aws ec2 describe-instances --instance-ids <healthy-node> \
--query "Reservations[0].Instances[0].SecurityGroups[*].[GroupId,GroupName]"
sg-09fa2xxxxxxxxxx healthy-prod-eks-node-xxxxx
정상 클러스터 노드 SG: LBC가 자동 추가한 인바운드 룰이 존재한다
$ aws ec2 describe-security-groups --group-ids sg-09fa2xxxxxxxxxx \
--query "SecurityGroups[0].IpPermissions[?Description==\
'elbv2.k8s.aws/targetGroupBinding=shared']"
IpProtocol: tcp
FromPort: 3000 ToPort: 8082
Source: sg-093aexxxxxxxxxx (ALB backend SG)
elbv2.k8s.aws/targetGroupBinding=shared라는 description이 달린 인바운드 룰이 있다. 이것이 LBC가 자동으로 추가한 룰이다. “ALB backend SG에서 포트 3000~8082로 들어오는 TCP 트래픽을 허용”한다는 의미이고, 이 덕분에 ALB가 Pod에 도달할 수 있다.
문제 클러스터의 노드 SG에는 이 룰이 없었다. LBC가 에러를 내고 추가하지 못했기 때문이다.
정상 클러스터 Terraform: 해당 설정이 없다
# 정상 클러스터 eks.tf
# attach_cluster_primary_security_group 설정 자체가 없음
# terraform-aws-eks 모듈 기본값: false차이는 이 설정 하나뿐이었다.
근본 원인
전체 인과관계를 하나의 흐름으로 정리하면 이렇다.
flowchart TD A["Terraform:<br/>attach_cluster_primary_security_group = true"] --> B["노드 Launch Template에<br/>클러스터 Primary SG 추가"] B --> C["노드 ENI에 SG 2개 연결<br/>노드 SG + 클러스터 SG"] C --> D["둘 다 kubernetes.io/cluster 태그 보유"] D --> E["LBC: 태그된 SG 2개 발견<br/>'어느 SG에 룰을 추가해야 하는가?'"] E --> F["판단 불가 → 에러 → 인바운드 룰 추가 포기"] F --> G["ALB → Pod IP:7001 트래픽이<br/>SG에서 차단됨"] G --> H["Target Group health check timeout"] H --> I["모든 타겟 unhealthy<br/>→ ALB가 504 반환"] style A fill:#fff3cd style F fill:#f8d7da style I fill:#f8d7da
두 클러스터의 차이를 나란히 놓으면:
graph TB subgraph "문제 클러스터 — 504" direction TB ALB_E[ALB] -->|"health check"| SG_E{"노드 SG<br/>인바운드 룰 없음"} SG_E -.->|"차단"| Pod_E[Pod] LBC_E["LBC"] -.->|"에러: 태그된 SG 2개<br/>룰 추가 포기"| SG_E style SG_E fill:#f8d7da end subgraph "정상 클러스터" direction TB ALB_R[ALB] -->|"health check"| SG_R{"노드 SG<br/>인바운드 룰 있음"} SG_R -->|"허용"| Pod_R[Pod] LBC_R["LBC"] -->|"태그된 SG 1개<br/>룰 자동 추가"| SG_R style SG_R fill:#d4edda end
해결 방법
기본값이 false이므로, 해당 줄 자체를 삭제했다.
eks_managed_node_groups = {
app = {
use_custom_launch_template = true
use_name_prefix = false
iam_role_use_name_prefix = false
- attach_cluster_primary_security_group = true
}
}terraform apply 이후의 동작:
sequenceDiagram participant TF as Terraform participant LT as Launch Template participant ASG as Auto Scaling Group participant Node as 노드 participant LBC as LB Controller participant SG as 노드 SG TF->>LT: Launch Template 업데이트<br/>(클러스터 SG 제거) LT->>ASG: Rolling Update 시작 ASG->>Node: 새 노드 생성<br/>(노드 SG만 연결) ASG->>Node: 기존 노드 drain & 삭제 LBC->>SG: 태그된 SG 1개 발견<br/>→ 인바운드 룰 추가 Note over SG: ALB → Pod 포트 허용 Note over Node: ALB health check 통과<br/>504 해소
Launch Template이 변경되므로 노드 교체(rolling update)가 발생한다. 실제 소요 시간은 약 12분이었다. 기존 노드가 drain되고 새 노드로 Pod가 옮겨가는 과정이 수반되므로, PDB(PodDisruptionBudget)가 설정되어 있는지 확인하고 서비스 영향을 고려하여 적용 시점을 선택해야 한다.
적용 후 확인:
$ curl -sk https://api.example.com/readyz
{"status":"ready"}
HTTP 200
504가 해소되고 정상 응답이 돌아왔다.
이 장애가 남긴 것
이 문제의 까다로운 점은, attach_cluster_primary_security_group = true가 그 자체로는 에러를 만들지 않는다는 것이다. 노드는 정상적으로 뜨고, Pod도 잘 돌아가고, kubectl로 보면 모든 것이 정상이다. 문제는 ALB를 통한 외부 트래픽이 처음 들어오는 시점에야 비로소 드러난다.
terraform-aws-eks 모듈은 attach_cluster_primary_security_group의 기본값을 false로 두고 있다. 이 기본값에는 이유가 있다. 모듈이 이미 노드 SG에 Control Plane ↔ 노드 통신에 필요한 모든 포트 룰을 자동으로 만들어주기 때문에, 클러스터 SG를 노드에 붙일 필요가 없다. 기본값을 바꾸려면, 왜 바꾸는지 명확한 이유가 있어야 한다.
이번 경우에는 인프라 코드 작성을 AI에게 맡기는 과정에서 발생했다. AI가 EKS 노드그룹 설정을 생성할 때 attach_cluster_primary_security_group = true를 포함했고, 나는 이 옵션의 의미를 충분히 이해하지 못한 채 승인했다.
AI가 생성한 코드라고 해서 신뢰도가 낮은 것은 아니다. 문제는 생성된 설정의 의미와 영향을 리뷰어가 검증하지 않았다는 점이다. 특히 기본값과 다른 설정이 들어있을 때는, 왜 기본값을 바꾸는지에 대한 명확한 이유가 있어야 한다.
부록: attach_cluster_primary_security_group은 언제 사용하는가
EKS의 두 가지 SG 운영 방식
이 옵션의 존재 이유를 이해하려면, EKS에서 Control Plane과 노드가 어떻게 통신하는지를 알아야 한다.
EKS Control Plane(API Server 등)은 AWS가 관리하는 별도의 VPC에 있고, 사용자의 VPC에 ENI를 꽂아서 노드와 통신한다. 이 통신을 위한 SG 설정 방식이 두 가지 있다.
graph TB subgraph "방식 A: 클러스터 SG 공유 (attach = true)" CP_A["Control Plane ENI"] --- CSG_A["클러스터 SG<br/><small>self-ref: 모든 트래픽 허용</small>"] Node_A["노드 ENI"] --- CSG_A Node_A --- NSG_A["노드 SG"] Note_A["장점: 포트별 룰 설정 불필요<br/>단점: LBC와 충돌 가능"] end subgraph "방식 B: SG 분리 (attach = false, 기본값)" CP_B["Control Plane ENI"] --- CSG_B["클러스터 SG"] CSG_B -.->|"포트별 룰<br/>10250, 443,<br/>4443, 6443..."| NSG_B Node_B["노드 ENI"] --- NSG_B["노드 SG"] Note_B["장점: LBC와 호환, 역할 명확<br/>단점: 포트별 룰 필요<br/>(모듈이 자동 생성)"] end style Note_A fill:#fff3cd style Note_B fill:#d4edda
방식 A (attach = true): 클러스터 SG를 Control Plane과 노드가 공유한다. 같은 SG끼리는 모든 트래픽이 허용되므로(self-referencing 룰), 개별 포트를 열어주지 않아도 양방향 통신이 된다. 간편하지만, 이 글에서 보았듯이 LBC의 SG 자동 관리와 충돌할 수 있다.
방식 B (attach = false, 기본값): 노드에는 노드 SG만 연결한다. Control Plane → 노드로 필요한 포트(kubelet 10250, webhook 4443/6443/8443/9443 등)를 노드 SG에 개별적으로 열어준다. terraform-aws-eks 모듈이 이 룰들을 자동으로 생성해주므로 수동 작업은 필요 없다.
어떤 방식을 선택해야 하는가
terraform-aws-eks 모듈을 사용한다면, 방식 B(기본값)로 충분하다. 모듈이 node_security_group_enable_recommended_rules = true(기본값)일 때 kubelet, webhook, CoreDNS, ephemeral ports 등 필요한 모든 포트 룰을 자동으로 생성해주기 때문에 방식 A의 편의성이 필요하지 않다. terraform-aws-eks FAQ에서도 방식 A와 방식 B를 혼용(노드 SG와 클러스터 SG를 둘 다 노드에 붙이는 것)할 때의 충돌을 경고하고 있다. (terraform-aws-eks FAQ)
이 문제를 만났을 때
증상: Pod 내부에서 health check가 정상인데 ALB가 504를 반환한다.
확인 순서:
- Target Group health 확인 —
Target.Timeout이면 SG 문제 가능성이 높다 - LBC 로그 확인 —
expected exactly one securityGroup에러가 있는지 확인한다 - 노드 SG 확인 —
kubernetes.io/cluster/{name}태그가 달린 SG가 2개 이상인지 확인한다 - Terraform 설정 확인 —
attach_cluster_primary_security_group = true이면 제거한다 - LBC 인바운드 룰 확인 — 노드 SG에
elbv2.k8s.aws/targetGroupBinding=shared룰이 있는지 확인한다. 이 룰이 없다면 LBC가 정상 동작하지 않은 것이다.
참고로, attach_cluster_primary_security_group을 제거하지 않고도 우회하는 방법이 있다. LBC의 --backend-security-group 플래그(Helm values: backendSecurityGroup)를 사용하면, ENI의 클러스터 태그 기반 자동 탐색을 건너뛰고 명시적으로 지정한 SG에 인바운드 룰을 추가한다. 다만 이 방식은 근본 원인을 해결하는 것이 아니라 우회하는 것이므로, 가능하다면 설정 자체를 제거하는 것이 낫다. (LBC Configurations 문서)